Где взять бесплатные прокси? Часть 2: Парсим бесплатные прокси листы
Тут проблем меньше, чем со сканированием всего интернета, нужно лишь скравлить несколько разных сайтов и слить списки проксей в 1 итоговый файл.
Нам нужен скриптик, который обойдёт все странички таблицы со списком проксей, вытащит данные и сохранит в цсв.
Для первой тренировки возьмём всем известный hidemy.name.
Подготовка констант
Сперва опишем стартовые константы: с какого урла начинать, css селекторы для таблички и ссылки на следующую страницу итд:
const cheerio = require('cheerio');
const getHTML = require('./libs/getHTML');
const writeCSV = require('./libs/writeCSV');
const startUrl = 'https://hidemy.name/ru/proxy-list/?type=h#list';
const baseUrl = 'https://hidemy.name';
const tableRowSelector = '.inner .table_block tr';
const nextPageLinkSelector = '.pagination .next_array a';
const addrColIndex = 0;
const portColIndex = 1;
const proxyType = 'http';
const dstFile = './result.csv';
const headers = {
'Cookie': '__cfduid=df0f27963f74bedac8295bbbf4bf616cd1578833620; t=152631734; jv_visits_count_PeHzjrJoSL=3; cf_clearance=6be6588940ec85d25a629574413d8d1d798c5f42-1579771170-0-150; jv_enter_ts_PeHzjrJoSL=1579771172995; jv_pages_count_PeHzjrJoSL=6'
}
Нам потребуются несколько вспомогательных функций, для красоты вынесем их в отдельные либы:
Получение html страницы по урлу:
const axios = require('axios');
const defaultHeaders = {
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'https://www.google.com/',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'TE': 'Trailers'
}
function getHTML(url, headers={}) {
let _headers = Object.assign({}, defaultHeaders);
for(let hName in headers)
_headers[ hName ] = headers[ hName ];
return axios({
method: 'get',
url: url,
timeout: 15000,
headers: _headers
});
}
module.exports = getHTML;
На большинстве сайтов будет стоять какая-то защита от ботов, и нам нужно прикинуться нормальным браузерм. По этому у нас описаны всевозможные хэдеры, а ещё добавлена возможность изменить дефолтные хэдеры, если это понадобится(а нам это понадобится).
Сохранение результатов в цсв:
const fs = require('fs');
const outHeaders = [ 'addr', 'port', 'type' ];
function writeCSV(outFile, data) {
let str = outHeaders.join(',') + '
';
for(let line of data) {
let outCol = [];
for(let h of outHeaders)
if( line[ h ] )
outCol.push(line[ h ]);
else
outCol.push('');
str += outCol.join(',') + '
';
}
fs.writeFileSync(outFile, str, { encoding: 'utf8' });
}
module.exports = writeCSV;
Пишем сам кравлер
Алгоритм простой:
- Запрашиваем первую страницу
- Ищем ней таблицу с результатами, строчка за строчкой её парсим
- Результату сохраняем в массив
- Ищем ссылку с урлом на следующую страницу
- Если нашли, возвращаемся к п.1 Если нет, то сохраняем результат и выходим
async function main() {
let result = [];
let eof = false;
let raund = 0;
let url = startUrl;
while( !eof ) {
console.log('Raund:', raund, 'url:', url);
let webResponse = await getHTML(url, headers);
let webData = webResponse.data;
let $ = cheerio.load(webData);
let targetTable = $(tableRowSelector);
for(let i=1; i<targetTable.length; i++) {
let tdList = cheerio('td', targetTable[ i ]);
let addr = cheerio(tdList[ addrColIndex ]).html();
let port = cheerio(tdList[ portColIndex ]).html();
result.push({ addr: addr, port: port, type: proxyType });
}
let nextPageUrl = $(nextPageLinkSelector);
if( nextPageUrl.length ==0 ) {
eof = true;
} else {
raund ++;
url = baseUrl + nextPageUrl[ 0 ].attribs.href;
}
}
writeCSV(dstFile, result);
}
Проверяем что получилось:
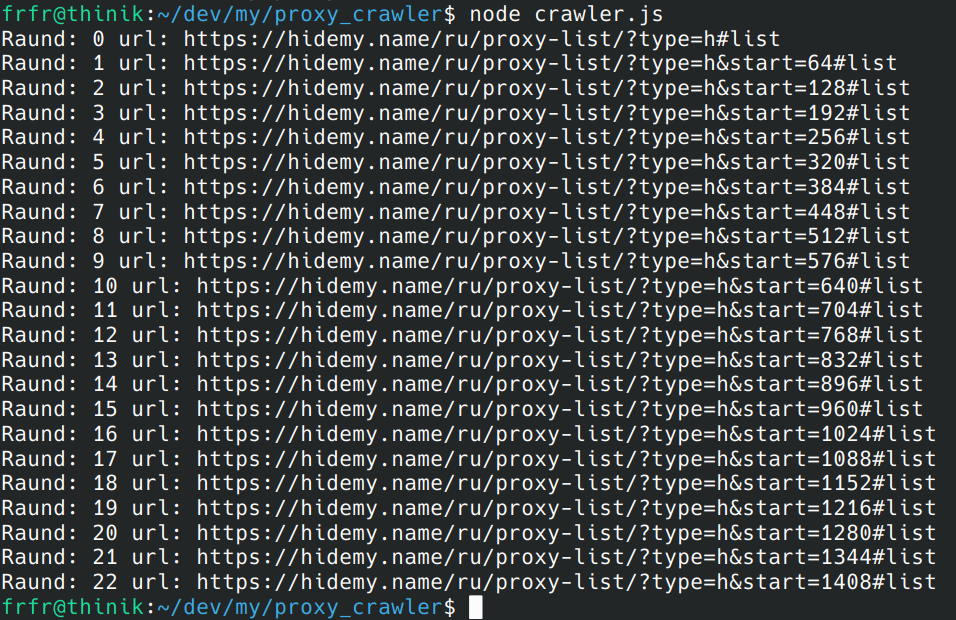
Всё скравлилось корректно, результаты в цсвшке сохранены.
Переходим на следующий сайт: free-proxy-list.net
На нём ситуация ещё более простая, вся таблица загружается целиком. Меняем константы:
const startUrl = 'https://free-proxy-list.net/';
const baseUrl = 'https://free-proxy-list.net/';
const tableRowSelector = '#proxylisttable tr';
const nextPageLinkSelector = '.any_random_class';
const addrColIndex = 0;
const portColIndex = 1;
const proxyType = 'http';
const dstFile = './free-proxy-list.net.csv';
В nextPageLinkSelector нужно поставить в любой несуществующий селектор, чтобы кравлер сразу остановился. Ну и пробуем, запускаем:

Всё отработало без ошибок, результаты в цсв сохранились.
Как это использовать на других сайтах?
Алгоритм одинаковый для любого сайта где есть табличка:
- Открываем стартовую страниу
- С помощью инструментов разработчика находим подходящий селектор для строк таблицы, записываем его в tableRowSelector
- Находим селектор для ссылки на следующую страницу, записываем его в nextPageLinkSelector
- Не забываем про остальные константы
- Запускаем
- ???
- Profit!
Как обойти защиту cloudflare (или любую другую)
Если клаудфлера не будет пропускать наш запрос, то заходим на сам сайт, открываем инструменты разработки, и копипастим курл запрос:
Из этого запроса нужно вытащить куки и вставить в эту константу::
const headers = {
'Cookie': '__cfduid=df0f27963f74bedac8295bbbf4bf616cd1578833620; t=152631734; jv_visits_count_PeHzjrJoSL=3; cf_clearance=6be6588940ec85d25a629574413d8d1d798c5f42-1579771170-0-150; jv_enter_ts_PeHzjrJoSL=1579771172995; jv_pages_count_PeHzjrJoSL=6'
};
После чего клаудфлера подумает, что это наш браузер и пропустит нас.
Сливаем все цсв в 1 итоговый
После того, как мы перекравлели пачку сайтов, нужно все результаты слить в 1 файл, да ещё и убрать дубликаты, наверняка большая часть проксей кочует с одного сайта на другой. Для этого напишем отдельный специализированный скриптик:
'use strict';
const fs = require('fs');
const writeCSV = require('./libs/writeCSV');
function parseCsv(srcString) {
let result = [];
let headers = [];
let lines = srcString.split('
');
for (let name of lines[ 0 ].split(',')) {
headers.push(name.trim());
}
for (let lineIndex = 1; lineIndex<lines.length; lineIndex++) {
let cols = lines[ lineIndex ].split(',');
let resLine = {};
for (let colIndex = 0; colIndex<headers.length; colIndex++) {
if ( cols[ colIndex ] ) {
resLine[ headers[ colIndex ] ] = cols[ colIndex ].trim();
}
}
result.push(resLine);
}
return result;
}
function main() {
if( !process.argv[ 2 ] || !process.argv[ 3 ] ) {
console.error('Not enough arguments');
console.error('usage: node merge_scv.js src_dir dst_scv_file');
}
let dirFiles = fs.readdirSync(process.argv[ 2 ], { encoding: 'utf8' });
let result = {};
for(let fileName of dirFiles)
if( /.csv$/gi.test(fileName) ) {
console.log('File:', fileName);
let curSCV = parseCsv(fs.readFileSync(`${process.argv[ 2 ]}/${fileName}`, { encoding: 'utf8' }));
for(let line of curSCV)
result[ line.addr + ':' + line.port ] = line;
}
// Then save results
let resArray = [];
for(let key in result)
resArray.push(result[ key ]);
writeCSV(process.argv[ 3 ], resArray);
}
main();
Запускаем и сливаем всё в 1 итоговый файлик:

Итого
Парсить научились, сливать цсв научилисю, весь проект на гитлабе: https://gitlab.com/hololoev/proxy_crawler
Комментариев(0)
